|
***STAR Star Worms: The Motion Picture Overview of
the game The player
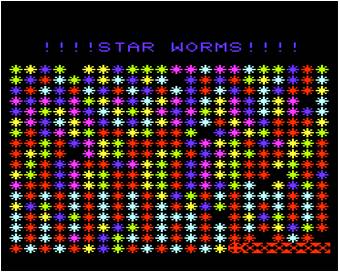
pilots worms through a colorful star field laced with dangerous black holes.
The History of Star Sometime around 1982, I was cleaning a glass coffee maker and I
dropped it on the tile counter top.
Instinctively trying to catch it, I lacerated my left hand so badly
that I needed plastic surgery in the emergency room to put it back
together. Then I had a week to spend
at home, with my hand held up in the air (because Dr. Simon said so). I decided to spend the time learning about
our VIC-20 computer. The name of the game came to me first. I’m sure the worms part came from reading Dune, and Star Wars was big at that time.
I liked “Star Worms” so much that I had to do something with it. The name has since been used for a bad
movie and other games. I claim that I
was the first to use it. The game was pretty much dictated by my programming
limitations. I had done some Fortran
and Basic programming, but never any graphics or machine language. Actually, this game has no graphics. Everything is done by changing the characters
in an 18 x 22 grid. I designed new
characters for the head and body of the worm so the worm could go in any
direction without changing the head.
That’s as close as I got to graphics. I wrote the game in a week with my right hand (I am left handed)
while keeping my left hand over my head.
Some time was spent learning VIC-20’s version of Basic and trying to
squeeze the program into the its tiny memory.
If you look at the puny listing, you will be surprised that I had
to worry about the size of the program. I persuaded the kids to play it a few times. Actually, I think it was their third or
fourth favorite video game. I don’t
know exactly because I can’t remember if we had two, or three, other games. We sold the VIC-20 at a garage sale, but I kept the Star Worms
tape. A couple of decades later, I
heard that there were VIC-20 emulators, but I didn’t have a listing of the
program and I couldn’t figure out how to get it off the tape. Then, in April 2006, I ran across the tape
and decided to take a stab at it. The
breakthrough came when I learned about programs that would convert a sound
file made from a tape into a file that could be run on an emulator. After some experimentation and tweaking, I
got it running. The kids are grown up, so I can’t make them play the game. It might be a good game for small
kids. Tell them that it doesn’t hurt
the worms when they get sucked into a black hole. They just go into an alternate universe
where there are no giant birds. And it
doesn’t matter if they eat the stars; there are billions, and we are making
more all the time. But little kids
these days have better things to do. So, this is just a family heirloom, like those locks of hair
from the kids’ first haircuts that are in the back of some drawer. Thanks to the people who have written this
great software that gets a modern computer to behave like a 1khz machine with
5k RAM, it will be preserved for future generations to marvel over how
impoverished we were in the early days of personal computing. If you have an interest in the VIC-20, or the game, for some
reason (maybe you have played every other game and this is the only one
left), here is what you need to get it running. 1.
You need a VIC-20 emulator. I used VICE.
It’s free, and an impressive piece of software. 2.
The game program is on StarWorms.tap. (Right click the link and then click "Save link as..." or "Save target as...") 3.
Start the emulator (xvic.exe if you are using
VICE). 4.
Make sure that Memory, under Settings/VIC
settings… is set to “no expansion memory.”
If you get an “OUT OF MEMORY” message from the emulator, you have too much memory in your virtual
VIC. Go figure. It took me a while to puzzle that one
out. My original VIC had no extra
memory, and the program addresses specific locations, so the virtual VIC has
to match it. 5.
Click File/Autostart disk/tape image… 6.
Select the StarWorms.tap file. 7.
Click the Attach button. 8.
Wait a couple of minutes (remember, we are back
in 1982) until the opening Star Worms screen appears. 9.
The number pad is used to emulate the joy
stick. The numbers 1-9 direct the worm
and 0 stops it. Links and
thanks I posted a message to comp.sys.cbm
and got very helpful replies from David Murray and Anders Carlsson. I used Tape64 (ftp://ftp.zimmers.net/pub/cbm/transfer/datassette/) and Audiotap (http://wav-prg.sourceforge.net/) to convert my wav file to tap.
Both seem good. Tape64 provided
the breakthrough because it allowed me to adjust the speed to 1.1. It took a lot of experimentation to convert
the file properly. I also had to learn
not to worry when the VICE emulator showed the contents of my file as “EMPTY
IMAGE.” As I mentioned before, VICE is a very impressive emulator. This stuff is all free, as is Star
Worms, but the other programs are really good. Return to Scotland-Stewart.com |